Overview
When dealing with several or millions of IoT devices the amount of data can quickly become overwhelming to your processing logic and storage solution. To begin reducing the complexity of dealing with the data, it’s helpful to group the data into one of two main categories: hot or cold. That is to say: does the data need to be analyzed immediately (hot), or can we look at the data at our own convenience (cold).
After the data is ingested and initial processing is complete, it needs to be stored. Is the data similar enough that it can be logged in a database (structured), or does it vary widely and needs more flexible data storage (unstructured). Also, how much data are you expecting to collect: petabytes, or megabytes? Who needs access to the data for analysis, and what if they’re located on the other side of the world? The delays in processing gigabytes of data while dealing with the latency of traversing the globe can quickly become frustrating.
These are all things that need to be thought through before you begin development. Hopefully, this helps provide some assistance with planning your IoT solution. If you have any additional questions or need help with your IoT solution, send us an email.
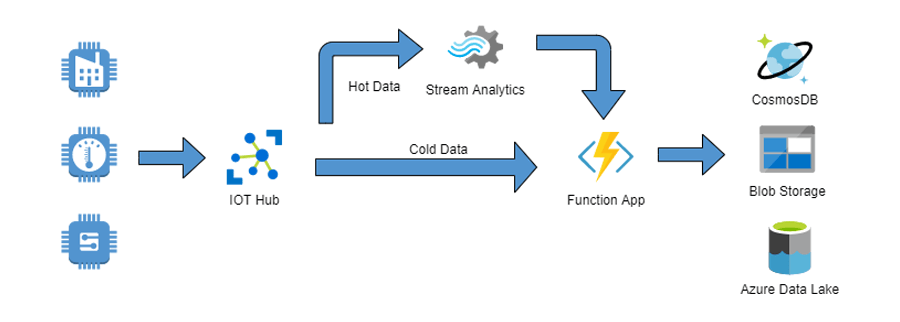
Data Processing
When your IoT nodes start producing data the server(s) need to be ready to handle that data as efficiently as possible, which means you need to determine if data is ‘hot’ or ‘cold’.
Hot Data
An example of ‘hot’ data might be motor speed. Perhaps the motor can run up to 110% of its nominal speed for up to 5 seconds without issue, but if it exceeds 115% for more than 5 seconds it needs to be disassembled and internal parts replaced. The motor speed information needs to be analyzed and acted upon quickly to avoid downtime and costly repairs.
Cold Data
‘Cold’ data, on the other hand, might be information like the volume of liquid pumped by the motor over the last 5 minutes. Knowing the exact flow at every given moment might not provide any valuable insights, so cold data can be batched and processed when reasonable.
To complicate matters more, hot and cold data is more of a sliding scale, with common nomenclature of ‘hot’, ‘warm’, ‘cool’, and ‘cold’. Data may not fall into a single category. Using the motor speed example from above; the motor speed may also need to be processed as cool or cold data because analysis has shown that motor speed tends to increase marginally day over day before motor failure. So, not only is the real-time data important but saving the data for later to identify trends may also be important. This dual processing path is quite common.
Structured vs Unstructured
Will all the IoT nodes produce data with the same type of structure or parameters; or is each node unique and there’s little to no overlap of the data structure between nodes?
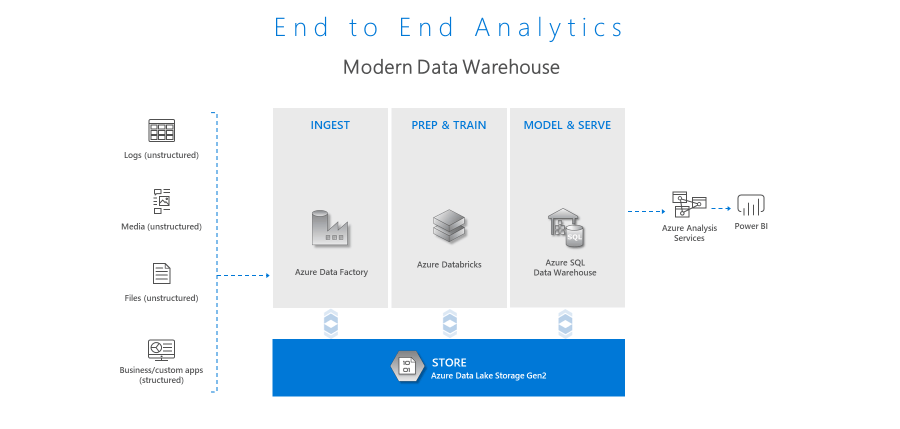
Image credit to Microsoft.
Blob Storage
To log unique (unstructured) data, Azure Storage Blob is likely your best option. It’s not as unmanageable as ‘blob’ makes it sound, that’s just referring to the fact that it’s meant to hold different types and models of data from videos and text, to pictures and audio recordings. Blob storage is pretty analogous to what you’re used to with your desktop or laptop computer with having different folders that contain other folders or files with lots of different file types. It’s the default storage option when creating a storage account.
Blob storage can be broken down into 3 types: Append, Page, Block.
- Append: Data can only be appended to the blob. Think a log file, new log entries are appended to the end and the blob continues to grow.
- Page: Good for data that needs frequent read/write access with high performance and low latency. General-purpose storage.
- Block: Block type storage is optimized for large data sets and provides parallel read/write to different blocks. It's for handling large (Gb’s) files over the network.
Page and Block type Blob storage can handle up to Terabytes of data, but there comes a point where an organization of ‘Big Data’ starts to become a limiting factor. Your data is worthless if you can’t efficiently query it. That’s when you need to consider a solution like Azure Data Lake. Data Lake provides additional organizational and security tools, as well as some built-in analytics.
CosmosDB
If the data is in a more consistent format, you may want to consider CosmosDB as the storage solution instead of blob storage. CosmosDB provides several features that may be beneficial for your organization and your data. Similar to SQL databases, CosmosDB provides the option to specify indexes on the data which can significantly improve query performance.
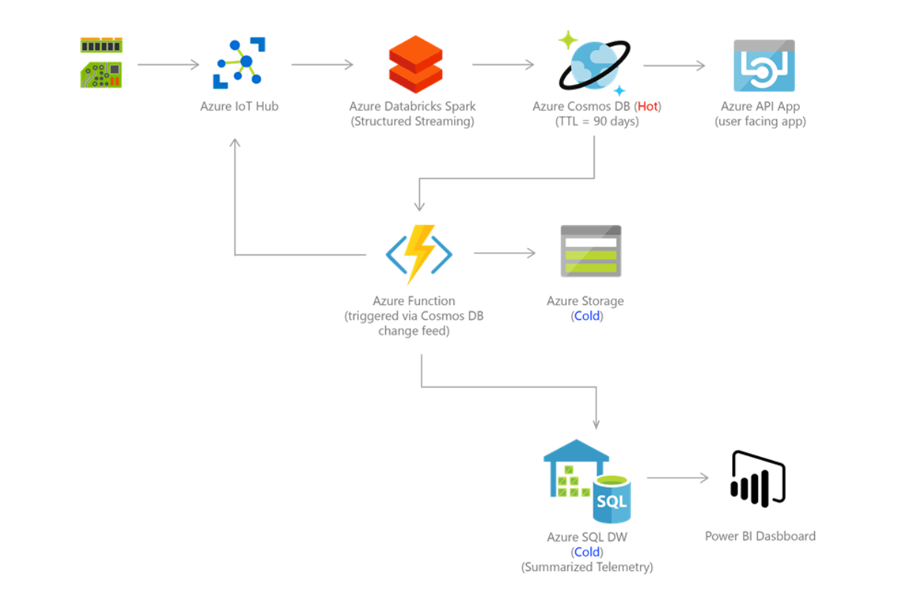
Image credit to Microsoft.
Also, CosmosDB was built with data sharing and replication in mind. A CosmosDB database can be configured to replicate data to multiple Azure regions around the globe giving employees in both North America and Australia, for example, access to the same data at the same time. It’s also possible for both regions to write data back into Cosmos at the same time. This is all in addition to a failover location which can be configured to take over operations in the event of a natural disaster or civil disturbance in the primary location.
Learn more about DMC's IoT solutions and Azure solutions. Contact us for more information.