I had a customer that wanted a Business Intelligence SharePoint web-part to track their facebook fans over time, to measure the effectiveness of their Facebook marketing push. Little did I suspect that I would be a casualty in the wars over database scalability.
I was excited because I'd heard great things about the active Facebook developer community, and found that the Facebook Query language (FQL) API was quite mature compared with other REST APIs that I had worked with, and even found a great .NET SDK for interfacing with Facebook.
Like most of our SharePoint web-parts, the intent seemed simple: use the API to get the list of fans/friends and the dates that they started following, group by the dates, and display to our existing SharePoint Charting web-part. In fact, the functionality sounded exactly like Facebook's existing 'friends timeline' feature, so I thought I would find most of this code already written and make quick work of it.
Then I learned that Facebook had removed the friends timeline in April of 2008, and was surprised to learn why.
The problem was Facebook's success - you see as databases scale up from simple millions of records to hefty billions or trillions per table, accessing data quickly can't just be solved with a faster server. This is an order of magnitude difference and requires a fundamental rethinking from traditional relational database architecture.
- First of all, searching against a non-indexed column is not allowed. These non-indexed searches require comparison against every record to evaluate, and countless additional queries could be done in that time instead.
- Next, the indices are so large and intensive that you don't want to create more than is absolutely necessary for core functionality.
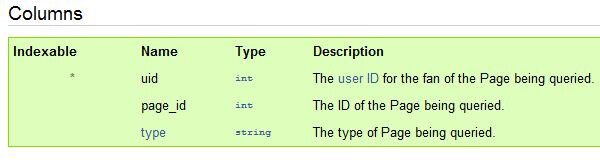
- Narrow tables with only the required information are preferred - most FQL tables have 2 columns relating a single userID with another User, Event, or Page.
Facebook knew that they needed a better database to keep up with their growth (incidentally, Facebook just surpassed Google's traffic). In April of 2008 Facebook finally switched to their own internally developed Cassandra database and altered their existing FQL public data interface appropriately. Its success made Cassandra a viable competitor with other highly scalable databases such as Amazon's S3, Google's BigTable, and Microsoft's Azure. The companies that truly need this kind of scalability are few but highly recognizable, so the competition in this new market is fierce. Twitter, and Digg have just converted to Cassandra, and Microsoft's Azure is finally ready for market and cloud hosting.
It's a brave new world of speed and scale, but it did squeeze my SharePoint web-part into a corner: The FQL Page_fan table no longer recorded the fan start date, so I would have to track fans over time myself to know the start-dates (as I'd also done for Twitter tracking). But the bigger blow was that the Page_Fan table was now also only indexable by user. Facebook had determined that it was more likely that apps would be searching for all pages associated with a single user than to search for all the users of a single page. Eliminating this index helped to speed up the whole, but means I couldn't get a list of fans.
My end solution was a Windows Service that connects to the Facebook API every 10 minutes to gather the total number of Fans of the customer page, tracking user adds and deletions though the day like a stock ticker. The customer loved the solution, but I still shake my fist that we weren't able to obtain more detailed data mining to provide more useful user demographics like we did for Twitter.